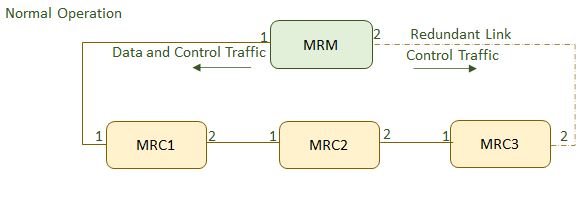
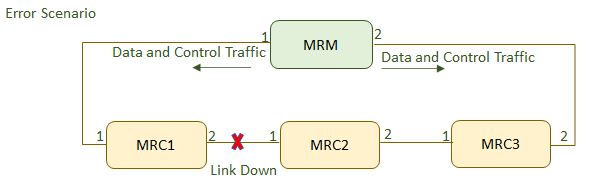
Redundancy within the network considers the presence
of more network elements (switches, link) than necessary operation,
in order to prevent the loss of communication caused by a failure.
To implement this, there is more than one physical path between
any two nodes. As per the IEC 61918 specified ring topology, every
switch has a redundant connection (link) into the network. The redundant
links are not required for a failure-free/normal operation of the
network; however, in case of a failure, these redundant links are
used to prevent the breakdown of the network. The disadvantage of
ring topology is that it can introduce a “packet loop” that creates
broadcast storms in the network.
Spanning Tree protocols (STP),
such as RSTP, specify a method
for providing media redundancy while preventing the undesirable
packet loop in a network. (i.e. RSTP was
developed to detect and eliminate the physical loop in the network).
Also, in case of a failure in the network, a topology change notification is
sent out to create a different safe path.
Although STP is effective enough
for many networks, it takes longer time for reconvergence in case
of failure. This is not good enough for mission-critical industrial
Ethernet applications.
To overcome the limitations of RSTP, MRP protocol was developed. MRP uses mechanisms similar to RSTP (e.g., deleting forwarding
database after reconfiguration, setting ports into blocking or forwarding mode),
but it takes lesser time for reconvergence in case of failure. Shown
below is the comparison between MRP and RSTP.
Table 1. Comparison
between MRP and RSTP
| |
MRP |
RST |
| Topology |
Ring |
Any |
| Number of switches |
50+ |
Maximum of 40 Switches |
| Recovery time |
Recovery time in case of a failure can run
into Less than 200ms |
Recovery time in case of a failure can run
into seconds depending on the topology and size of the network. |
| Configuration |
Simple |
Medium |